
Amsterdamse onderzoekers hebben een nieuw algoritme ontwikkeld om meer efficiënte deep learning-modellen te maken. Hiermee is het mogelijk neurale netwerken aanzienlijk te verkleinen. BrainCreators heeft dit nieuwe rekenvoorschrift FlipOut genoemd. Dankzij het algoritme hoeven organisaties straks minder opslagruimte te gebruiken. Een aanzienlijke besparing in energie en kosten zou mogelijk zijn. En dat terwijl het verlies aan nauwkeurigheid of prestaties tot een minimum wordt beperkt.
In de afgelopen tien jaar kwamen de best presterende ai-systemen, zoals de spraakherkenning op smartphones en automatisch vertalen, voort uit een techniek die deep learning wordt genoemd. Het succes van deep learning, een variant van machine learning, is grotendeels te danken aan het ontwikkelen van steeds grotere neurale netwerken. Hierdoor kunnen deep learning modellen beter presteren, maar zijn ze ook duurder in gebruik. Grotere modellen nemen immers meer opslagruimte in beslag, kosten meer tijd om te trainen en hebben vaak duurdere hardware nodig.
Model-compressie
Voor veel organisaties vormt dit een uitdaging, zodra ze een applicatie in productie willen nemen. Om deze uitdagingen op te lossen moeten organisaties de grootte van modellen verkleinen via een model-compressiemethode. Echter zorgt model-compressie ook vaak voor prestatieverlies, waardoor er een grote kans is dat het deep learning-model minder nauwkeurig opereert.
Onderzoekers Andrei Apostol, Maarten Stol en Patrick Forré combineerden in hun nieuwe algoritme neural network pruning met quantization-compressiemethodes. Bij neural network pruning worden de overtollige gewichten van een getraind model verwijderd, terwijl bij quantization het aantal bits wordt verminderd. Daardoor worden er minder berekeningen uitgevoerd. Het resulterende model zal kleiner worden.
Complementair
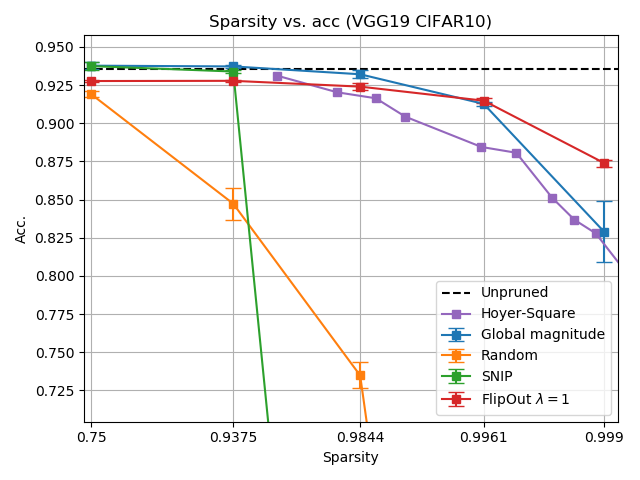
Als FlipOut alleen wordt toegepast middels neural network pruning, is het in staat om 90 procent van de verbindingen in de netwerken te verwijderen, zonder in te boeten in nauwkeurigheid of prestaties. Bij quantization is het algoritme in staat om de hoeveelheid bits te verkleinen van 32 tot 8 bits per verbinding.
De onderzoekers kwamen er tijdens hun onderzoek ook achter dat de twee methodes complementair zijn aan elkaar en heel goed samenwerken. Als de twee compressiemethodes worden gecombineerd, kan het algoritme driekwart van de verbindingen verwijderen, terwijl de gewichten met vier keer minder bits worden opgeslagen zonder verval in nauwkeurigheid.





